
Calcium imaging based on two-photon scanning microscopy is a standard method to record the activity of neurons in the living brain. Due to the point-scanning approach, sampling speed is limited and the dwell time on a single neuron reduces with the number of recorded neurons. Therefore, one needs to trade off the number of quasi-simultaneously imaged neurons versus the shot noise level of these recordings.
To give an simplified example, one can distribute the laser power in space and time over 100 neurons at 30 Hz, or 1000 neurons at 3 Hz. Due to the lower sampling rate, the signal-to-noise-ratio (SNR) of the 1000 neurons will decrease as well.
A standardized noise level
To compare the shot noise levels across recordings, in our recent paper (Rupprecht et al., 2021) we took advantage of the fact that the slow calcium signal is typically very similar between adjacent frames. Therefore, the noise level can be estimated by

The median makes sure to exclude outliers that stem from the fast onset dynamics of calcium signals. The normalization by the square root of the frame rate 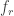
Why the square root? Because shot noise decreases with the number of sampling points with a square root dependecy. The only downside of this measure is that the units seem a bit arbitrary (% for dF/F, divided by the square root of seconds), but this does not make it less useful. To compute it on a raw dF/F trace (percent dF/F, no neuropil subtraction applied), simple use this simple one-liner in Matlab:
noise_level = median(abs(diff(dFF_trace)))/sqrt(framerate)
Or in Python:
import numpy as np noise_level = np.median(np.abs(np.diff(dFF_trace)))/np.sqrt(framerate)
If you want to know more about this metric, check out the Methods part of our paper on more details (bioRxiv / Nature Neuroscience, subsection “Computation of noise levels”).
The metric 
Comparison of noise levels and neuron numbers across datasets
I collected a couple of publicly available datasets (links and descriptions in the appendix of the blog post) and extracted both the numbers of simultaneously recorded neurons and the shot noise level

As a reference, I used the Allen Brain Institute Visual Coding dataset. For excitatory neurons, typically 100-200 neurons were recording with a standard noise level of 1 (units omitted for simplicity). If you distribute the photons across an increasing number of neurons, the shot noise levels should increase with the square root of this multiple (indicated by the black line). Datasets with inhibitory neurons (de Vries et al., red) have by experimental design fewer neurons and therefore lie above the line.
A dataset that I recorded in zebrafish with typically 800-1500 neuron per recording lies pretty much on this line, similar to the MICrONS dataset where they used a mesoscope to record from several thousand cortical neurons simultaneously, at the cost of lower frame rate and therefore higher noise levels, similar to the dataset by Sofroniew et al., which recorded ca. 3000 neurons, but all from one plane in a large FOV.
Two datasets acquired by Pachitariu and colleagues stands out a bit by pushing the number of simultaneously recorded neurons. In 2018, this came at the expense of increased noise levels (pink). In 2019 (a single mouse; grey), despite a dataset with ca. 20,000 simultaneously recorded neurons, the noise level was impressively low.
In regular experiments, in order to mitigate possible laser-induced photodamage or problems due to overexpression of indicators, noise levels should not be maximized at the cost of physiological damage. For example, the mouse from the MICrONS dataset was later used for dense EM reconstruction; any sort of damage to the tissue, which might be invisible at first glance, could complicate subsequent diffusive penetration with heavy metals or the cutting of nanometer-thick slices. As a bottom line, there are often good reasons not to go for the highest signal yield.
Spike inference for high noise levels
To give an idea about the noise level, here is an example for the MICrONS dataset. Due to the noisiness of the recordings (noise level of ca. 8-9), only large transients can be reliably detected. I used spike inference through CASCADE to de-noise the recording. It is also clear from this example that CASCADE extracts useful information, but won’t be able to recover anything close to single-spike precision for such a noise level.

Above are shown the smooth inferred spike rates (orange) and also the discrete inferred spikes (black). The discrete spikes (black) are nice to look at, but due to the high noise levels, the discretization into binary spikes is mostly overfitting to noise and should be avoided for real analyses. For analyses, I would use the inferred spike rate (orange).
Conclusion
The noise level
As a note of caution,
.
Appendix: Details about the data shown in the scatter plot
de Vries et al. (2020; red and black) describes the Allen Visual Coding Observatory dataset. It includes recordings from more than 100 mice with different transgenic backgrounds in different layers of visual-related cortices. Red dots are datasets from mice that only expressed calcium indicators in interneurons, while black dot are datasets with cortical principal neurons of different layers. The datasets are highly standardized and of low shot noise levels (standardized level of ca. 1.0), with relatively few neurons per dataset (100-200).
Rupprecht et al. (unpublished; green) is a small dataset in transgenic Thy-1 mice in hippocampal CA1 that I recorded as a small pilot earlier this year. The number of manually selected neurons is around 400-500, at a standardized noise level of 2.0-3.0. With virally induced expression and with higher laser power (here, I used only 20 mW), lower noise levels and higher cell counts could be easily achieved in CA1.
Rupprecht et al. (2021; violet) is a dataset using the small dye indicator OGB-1 injected in the homolog of olfactory cortex in adult zebrafish. At low laser powers of ca. 30 mW, 800-1500 neurons were recorded simultaneously at a standardized noise level of 2.0-4.0.
Sofroniew et al. (2016; light green) recorded a bit more than 3000 neurons simultaneously at a relatively low imaging rate (1.96 Hz). Different from all other datasets with >1000 neurons shown in the plot, they recorded only from one single but very large field of view. All neuronal ROIs had been drawn manually, which I really appreciate.
Pachitariu et al. (2018; pink) is a dataset recorded at a relatively low imaging rate (2.5 Hz), covering ca. 10,000 neurons simultaneously. The standardized noise level seems to be rather high according to my calculations.
Pachitariu et al. (2019; black) is a similar dataset that contains ca. 20,000 neurons, but at a much lower standardized noise level (4.0-5.0). The improvement compared to the 2018 dataset was later explained by Marius Pachitariu in this tweet.
MICrONS et al. (2021; red) is a dataset from a single mouse, each dot representing a different session. 8 imaging planes were recorded simultaneously at laser powers that would not damage the tissue, in order to preserve the brain for later slicing, with the ultimate goal to image the ultrastructure using electron microscopes. The number of simultaneously imaged neurons comes close to 10,000, resulting in a relatively high standardized noise level of 7.0-10.0.
[Update, November 2021] As has become clear after a discussion with Jake Reimer on Github, the MICrONS data that I used were not properly normalized; it was not proper dF/F but with a background subtraction. The noise measure for this dataset is therefore not very meaningful, unfortunately. My guess is that the true noise level is in the same order of magnitude as shown in the plot above, but I cannot tell for sure.
The black line indicates how the noise level scales with the number of neurons. For 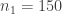

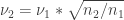

Hi Peter, did you repeat the noise level calculation on the dF/F trace for every cell, and then take the mean per animal for plotting purposes? I am not currently getting a comparable value for the noise level of my 2P data.
I am using suite2p for trace extraction, taking the F.npy and subtracting Fneu.npy (although tried without neuropil-subtraction, still very low noise levels), then doing dF/F calculation using:
flu_mean = np.mean(flu, 1)
flu_mean = np.reshape(flu_mean, (len(flu_mean), 1))
dff = (flu – flu_mean) / flu_mean
Where flu is a [cell x timepoint] array. My values are all coming out around 0.2-0.3, but I am imaging 2000-3000 neurons (1.4 mm) – I must be doing something wrong:
noise_levels = np.empty(exp.n_units)
for i, dff_trace in enumerate(dff):
noise_level = np.median(np.abs(np.diff(dff_trace)))/np.sqrt(exp.fps)
noise_levels[i] = noise_level
print(‘mean: {0:2f}’.format(np.mean(noise_levels)) + ‘\n’,
‘std: {0:2f}’.format(np.std(noise_levels, ddof=1))
)
Best,
Rob
Hi Rob, yes, I took the measure for every neuron and then averaged across neurons to get a data point.
A noise level of 0.2-0.3 for several thousand neurons would be extremely high, but maybe not impossible with strong viral expression and sufficient laser power. If the transients look really smooth and clean, such a low noise level is possible. In your case, I have the impression that you took dF/F as a numeric value, not as percent value. If you use the percent value, the formula changes into:
dff = (flu – flu_mean) / flu_mean * 100
In this case, you would get a noise value of 20-30, with everything else in your analysis unchanged. This would indicate relatively noisy recordings.
However, two things you should check:
1) Is the exp.fps correct?
2) Did you consider using the median or e.g. the 20th percentile to calculate the F0 value instead of the mean? Depending on the distribution of your fluorescence measurements and neuronal activity, these metrics might be more appropriate and, as a side-effect, result in a (numerically) lower noise level.
3) Try the noise level computation also without neuropil subtraction. The standard routine in Suite2p for neuropil subtraction (I think it’s subtracting 0.7*neuropil) can, under some conditions and depending on the relative brightnesses of neuropil and neuron, blow up the absolute values quite a bit. Most if not all (I don’t remember right now) of the values the plot were computed from data without neuropil subtraction. – I think you can see from that already a limitation of the noise level concept: A very blurry recording (e.g., 1P recording) would result in apparently low noise levels because the signal is smoothed out by the background. One of the reasons why it never makes sense to game a single metric …
Let me know if this helps or if anything remained unclear!
Best,
Peter
Thanks Peter, your comment was very helpful.
You are right, our dF/F was a numeric value, not a percentage. Changing to a percentage resulted in noise levels of 15-25. However, using no neuropil subtraction put it almost perfectly on the line of number of neurons vs. noise level. We were imaging 2000+ neurons (probably 3000 but we don’t pick them all up) and got a standardised noise level of between 4 and 5 for each animal.
Concerning Fo calculation, would you use mean for low firing rate neurons (cortical excitatory during spontaneous activity) and maybe median for higher firing rates (hippocampus?), or e.g. 20th percentile (or lower)? We are imaging cortical neurons in our dataset.
Thanks again,
Rob
Nice to hear that it comes out as consistent. Maybe I should add the information to use % values and no neuropil correction to compute the noise levels comparably …
For the F0 calculation, I think that there is no standardized recipe, and everybody does whatever they think works.
Even for low firing rate neurons, I would use the median rather than the mean, although the difference might be really small. Then, if there is higher activity, ideally I would gradually shift the percentile to lower value:
very low activity –> 50% percentile = median
high activity –> 20% percentile
very high activity –> 10% percentile
All these values of course depend on noise levels. If there is excessive noise, one cannot take the 10% percentile. If there is zero noise, one can take the 5% percentile.
And if there is some drift over longer time scales, one can apply a running median or running percentile filter. This is done for example by CaImAn and also by Suite2p (not entirely sure about the latter).
Pragmatically, I would just look at some traces, whether the baseline is close to zero. With our experience as humans we can judge it very easily what would be the best baseline; and maybe taking the mean, if you have little drift no sparse activity in cortex, might already do the job!
Best,
Peter
Pingback: Video introduction to CASCADE | A blog about neurophysiology
Pingback: Accuaretly computing noise levels for calcium imaging data | A blog about neurophysiology