
In a new article on Distill, Olah et al. write up a very readable and useful summary of methods to look into the black box of deep networks by feature visualization. I had already spent some time with this topic before (link), but this review pointed me to a couple of interesting aspects that I had not noticed before. In the following, I will write about one aspect of the article in more depth: whether a deep network encodes features rather on a neuronal basis, or rather on a distributed, network basis.
‘Feature visualizations’ as discussed here means to optimize the input pattern (the image that is fed into the network) such that it maximizes the activity of a selected neuron somewhere in the network. The article discusses strategies to prevent this maximization process from generating non-naturalistic images (“regularization” techniques). On a sidenote, however, they also asks what happens when one optimizes the input image not for a single neuron’s activity, but for the joint activity of two or more neurons.

Joint optimization of the activity of two neurons. From Colah et al., Distill (2017) / CC BY 4.0.
Supported by some examples, and pointing at some other examples collected before by Szegedi et al., they write:
Individual neurons are the basis directions of activation space, and it is not clear that these should be any more special than any other direction.
It is a somehow natural thought that individual neurons are the basis of coding/activation space, and that any linear combination could be used for coding equally well as any single neuron-based representation/activation. In linear algebra, it is obvious that any rotation of the basis that spans the coding space does not change anything about the processes and transformations that are taking place in this space.
However, this picture breaks down when switching from linear algebra to non-linear transformations, and deep networks are by construction highly non-linear. My intuition would be that the non-linear transformation of inputs (especially by rectifying units) sparsens activity patterns with increasing depth, thereby localizing the activations to fewer and fewer neurons, without any sparseness constraint during weight learning. This does not necessarily mean that the preferred input images of random directions in activation space would be meaningless; but it would predict that the activation patterns of to-be-classified inputs are not pointing into random directions of activation space, but have an activation direction that prefers the ‘physical’, neuronal basis.
I think that this can be tested more or less directly by analyzing the distributions of activation patterns across layers. If activation patterns were distributed, i.e., pointing into random directions, the distribution would be rather flat across the activation units of each layer. If, on the other hand, activation directions were aligned with the neuronal basis, the distribution would be rather skewed and sparse.
Probably this needs more thorough testing than I’m able to do by myself, but for starters I used the Inception network, trained on the ImageNet dataset, and I used this Python script on the Tensorflow Github page as a starting point. To test the network activation, I automatically downloaded the first ~200 image hits on Google for 100×100 JPGs of “animal picture”, fed it into the network and observed the activation pattern statistics across layers. I uploaded a Jupyter Notebook with all the code and some sample pictures on Github.
The result is that activation patterns are sparse and tend to become sparser with increasing depth of the layers. The distribution is dominated by a lot of zero activations, indicating a net input less or equal to zero. I have excluded the zeros from the histograms and instead given the percentage of non-zero activations as text in the respective histogram. The y-axis of each histogram is in logscale.
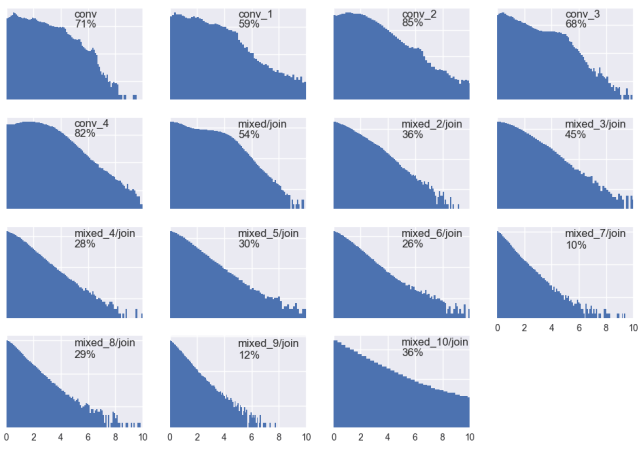
It is also interesting that the sparseness decreases with depth, but reaches a bottleneck at a certain level (here from ‘mixed_7’ until ‘mixed_9’ – the mixed layers are inception modules) and becomes less sparse afterwards when approaching the (small) output layer.
A simple analysis (correlation between activation patterns stemming from different input images) shows that de-correlation (red), that is, a decrease of correlation between activations by different input images, is accompanied by sparsening of the activation levels (blue):

It is a bit strange that the network layers 2, 4 and 6 generate sparser activations patterns than the respective previous layers (1, 3 and 5), accompanied by less decorrelated activity. It would be interesting to analyze the correlational structure in more depth. For example, I’d be curious to understand activation patterns of input patterns that lead to the same categorization in the output layer, and to see from which layer on they start to exhibit correlated activations.
Of course there is a great body of literature in neuroscience, especially theoretical neuroscience, that discusses local, sparse or distributed codes and the advantages and disadvantages that come with it. For example, according to theoretical work by Kanerva, sparseness of memory systems helps to prevent different memories from interfering too much with each other, although it is unclear until now whether something similar is implemented in biological systems (you would find many experimental papers with evidence in favor and against it, often for the same brain area). If you would like to read more about sparse and dense codes, Scholarpedia is a good starting point.

Pingback: Deep learning, part III: understanding the black box | A blog about neurophysiology
The following blog post might be interesting as well, shedding light onto sparseness of representations mostly from a machine learning point of view: http://blog.shakirm.com/2016/04/learning-in-brains-and-machines-2/