
How does the brain work and how can we understand it? To view this big question from a broad perspective at the end of each year, I’m reporting some of the thoughts about the brain that marked me most during the past twelve month – with the hope to advance and structure the progress in the part of my understanding of the brain that is not immediately reflected in journal publications. Enjoy the read! And check out previous year-end write-ups: 2018, 2019, 2020, 2021, 2022, 2023, 2024.
During the last years’ write-ups, I have been thinking about experiments to study self-organized plasticity in living brains. This year, I have been busy with preparations for the implementation of this line of research and hope to be working on it next year. Experimentally, I have been mostly occupied with – and more and more intrigued by – the study of hippocampal astrocytes and how they integrate calcium signals. In experiments connected to this project, we are now studying the role of neuromodulation and the locus coeruleus in more detail. And I’m glad that I can learn more about this interesting brain area by doing experiments myself. But I will discuss this in another blog post in more detail.
For this write-up, I want to discuss a small subfield of neuroscience that I only became aware of this autumn and that is closely related to ideas of self-organized neuronal networks: the experimental study of learning in cell cultures. How can the neuronal system of a cell culture be used to interact with a (virtual) world in a closed loop? In this blog post, I will discuss a few important papers to understand what can be studied with this model system of learning.
In conclusion, I think that this field is interesting in principle, as it provides a method to study plasticity (although this is not necessarily the primary aim of this kind of research). The method suffers from the problem, as most in vitro slice approaches as well, that experimental protocols for plasticity induction might be artificial and not related to processes in vivo.
I became aware if the field in October, when a high-profile paper on this topic came out and was prominently covered on social media – partly for making misleading claims and not citing prior research. I want to make it better and start chronologically with a seminal paper from 2001.
A network of cultured cortical neurons is trained to stop a stimulus
Shahaf and Marom showed in 2001 what can be described as “learning-in-a-dish” [1,2]. In these experiments, they grew a culture of cortical neurons on a 2D multi-electrode array (MEA) such that they could both stimulate these neurons and record from them. They used this system to provide some neurons with a specific stimulus. When the neuronal network exhibited a certain firing pattern briefly after stimulation, the stimulation was stopped. With this approach, the cultured network was embedded in a closed-cloop interaction.
Interestingly, the cultured network indeed started to increasingly show these spiking patterns that stopped the external stimulation. The observation is very easily summarized by figure 2 in their experimental paper [1]. After learning, the network is much more activate in a pre-defined time window (shaded area), thereby shutting down the stimulation:

This is a fascinating and also surprising observation. It seems as if the network is realizing that there is a stimulus, decides that the stimulus is annoying and therefore puts forward measures to stop and prevent the stimulus. Such a description is however highly anthropomorphic and does not really help to understand what is going on.
According to Shahaf and Marom, their observation shows in the first place that a neuronal network does not depend on a distinct implementation of reward or other forms of reinforcement. Instead, the network, following Shahaf and Marom, explores configurations until a desired state is reached (in this case: the state of stimulus removal) [1]. The authors discuss the implications a bit more in detail in [2] (check out section 7) but remain rather vague on the possible mechanisms of synaptic plasticity that might underlie such behavior.
A network of cultured cortical neurons interacts with a virtual world
Going slightly beyond the very simple closed loop by Shahaf and Marom, researchers from the lab of Steve Potter, which according to the lab’s website has “created the field of embodied cultured networks”, used the activity of the cultured neurons to drive the behavior of an “animal” in a virtual world [3]. The sensory feedback received by this animal in the virtual world is fed back to the cultured neurons. In this study, the focus is primarily on showing that it is possible to have a cultured network and a very simple virtual environment in a closed loop. This sounds particularly fascinating as the paper was published during a time when the movie Matrix had just come out.
Afterwards, in order to be able to evaluate learning and plasticity systematically, the lab moved to specific tasks based on this experimental design [4]. This study by Bakkum, Chao and Potter is conceptually close to the studies by Shahaf and Marom discussed above. The experimental design is depicted in this nice schematic (part of figure 1 in [4]) and shows a clearly identified mapping of the population activity onto a “motor output”.
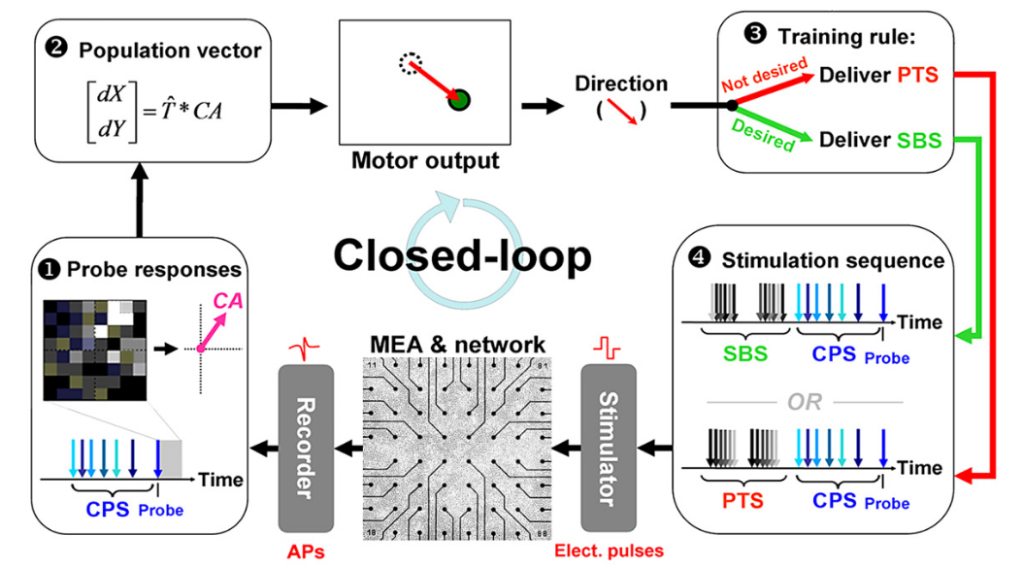
Here, SBS (unpatterned shuffled background stimulation) serves as a kind of reward or neutral stimulus while PTS (patterned training stimulation) serves as an aversive stimulus that makes the network provide different output activity patterns. The (unchanging) context-control probing sequence (CPS) is used as a probe, and the network response upon the CPS pattern is regarded as the system’s motor output. Therefore, PTS or SBS act as plasticity- or feedback-stimuli, whereas CPS defines a probing time window to elicit the “motor output”.
The authors show that the networks could learn to provide mostly correct motor output when trained with such a paradigm. In addition, they quantify plasticity processes over time. Plasticity was higher during the learning procedure compared to baseline and remained higher for >1h after training. To summarize, the authors do not dig into mechanisms of cell-to-cell plasticity but rather provide a broader, systemic description of what is going on.
A difficult-to-grasp feature of this experimental study is the design of the patterned training stimulations (PTSs). The authors repeatedly applied different stimulation patterns (e.g., PTS1 stimulates electrodes 1, 4, 7 and 15, PTS2 stimulates electrodes 6, 8, 19, 20, 21 with specific stimulation intensities). Their algorithm was designed to choose from a pool of PTSs and select the PTS that resulted in plasticity towards a network state that generated the desired “motor” output. In 2022, most people (or at least myself) are so much used to deep learning and gradient descent that it is almost strange to read about such a random exploration approach.
Interestingly, the authors also investigated a comparable paradigm in a separate and purely theoretical study [5]. In this study, they replaced the cultured network with a simulated network and found very similar learning compared to the in vitro study. They found that this behavior depended on spike-time dependent plasticity, a cell-to-cell synaptic plasticity rule, and on STD, a short-term plasticity rule that helps to prevent large system-wide bursts.
From my perspective, it is interesting to see that the cell culture results could be replicated with a network that was based on STDP. A large part of the paper however instead focuses on the question how to choose and adapt stimuli that make the network learn the desired output. I would have been interested to get to know more about how STDP is shaped by the stimulation patterns and driven towards the desired output.
Learning by stimulation avoidance and autopoiesis
The group of Takashi Ikegami tried to better understand what is actually going on when neuronal cultures as in the experiments by Shahaf and Marom [1] learn to shut down an external stimulus. They study this effect using simulated neuronal networks and, as in work from the Potter lab [5], they identify spike-timing dependent plasticity (STDP) as an essential factor to mediate this learning process. As in work from the Potter lab, they also use an “embodied” application with a moving simulated robot that learns to avoid walls [6].
The main take-away of their simulation experiments is that the experiments by Shahaf and Marom can be replicated in silico and that the observed phenomena can be interpreted as “Learning by Stimulation Avoidance (LSA)”. The authors write in the discussion:
LSA is not just an another theoretical neural learning rule, but provides a new interpretation to the learning behavior of neural cells in vitro. (…) LSA relies on the mechanism of STDP, and we demonstrated that the conditions to obtain LSA are: (1) Causal coupling between neural network’s behaviour and environmental stimulation; (2) Burst suppression. We obtain burst suppression by increasing the input noise in the model or by using STP.
I have the impression that this is an overstatement of what “LSA” is. First, both STDP and burst suppression by spontaneous activity as ingredients to enable learning-in-a-dish had been described already previously [5]. Second, I don’t think this is “a new interpretation” of in vitro learning but simply the demonstration of a model that is consistent with the observed experiments from [1].
The authors expand a bit and provide more context:
As we have shown, LSA does not support the theory of the Stimulus Regulation Principle. It could be closer to the Principle of Free Energy Minimisation introduced by Friston. The Free Energy Principle states that networks strive to avoid surprising inputs by learning to predict external stimulation.
The “stimulus regulation principle” suggests a network that samples possible network configurations and stops the exploration once a favorable state is reached. A favorable configuration would be one which manages to suppress the stimulation. The STDP-model put forward by [6] instead is based on a synaptic learning rule that specifically strengthens and weakens synapses in order to reach a favorable network configuration.
The mentioned “free energy principle”, on the other hand, is infamous for being so general that almost any imaginable theory is consistent with it. The most popular theory about an implementation of the free energy principle is probably predictive processing [7]. In classical predictive processing, an internal model in the brain provides top-down signals to cancel out expected sensory inputs. The internal model adapts in order to improve the predictive power of the top-down signals. It is interesting how this typically hierarchical top-down/bottom-up view breaks down when being applied it to the model system of a dissociated cell culture. It would be hard to assume that there is an hierarchy in this dish. And still, the stimulus-avoidance paradigm does have some clear resemblance with surprise-minimization and predictive processing.
For more work from the Ikegami lab in collaboration with others, check out [8], where they interpret the findings that neurons in cultured networks that receive incontrollable stimulation will be disconnected from the network. They do so in the context of the rather old concept of autopoiesis, thereby going beyond the simple principle of “learning by stimulus avoidance” (LSA).
A network of cultured cortical neurons learns to play a simplified version of pong
In October 2022, a related paper by Kagan et al. with Karl Friston as senior author – who is famous for inventing the free energy princple – was published [9]. It received a lot of attention, but also quite some criticism by several neuroscientists on Twitter (ref 1, ref 2, ref 3, and other discussions that were deleted afterwards). It was critizised that the paper failed to cite previous research and interpreted the results in a misleading manner. For example, the title speaks of cultured neurons that “exhibit sentience”. This statement does not use a commonly used definition of “sentience” and therefore seems quite misleading for the reader. Unfortunately, this is not the only part of the manuscript which sounds like a buzzword combination made up by ChatGPT. Check out this excerpt of the introduction:
Instantiating SBIs [synthetic biological intelligences] could herald a paradigm shift of research into biological intelligence, including pseudo-cognitive responses as part of drug screening, bridging the divide between single-cell and population-coding approaches to understanding neurobiology, exploring how BNNs compute to inform machine-learning approaches, and potentially giving rise to silico-biological computational platforms that surpass the performance of existing purely silicon hardware.
But let’s put all the the buzz aside and discuss the science. Similar to the previously discussed studies, Kagan et al. used cultured neurons that were integrated into a closed loop using multi-electrode arrays. The virtual environment of this closed loop was a simplified version of the game “pong”. The multi-electrode array (MEA) was used to provide the cell culture with “sensory” feedback about the position of the ball and the success of the game, and to provide “motor” output from the MEA activity pattern back to the game in order to control the paddle.

Pong as implemented in the paper was less demanding (using a paddle half as large as the side of the arena). Despite this simplification, the performance of the cell culture controlling the game was not very impressive. The cultured network, after some learning, managed to hit the ball on average a bit more often than once (1x) before losing the game. This performance is not much higher (but significantly above) chance level.
The experimental design is well illustrated by this panel from their figure 5 (taken from the preprint, which had been published under the CC-BY-NC-ND-4.0 license):

The electrode array is subdivided into a “sensory” region indicated by the crosses and a “motor” region indicated by up and down arrows; the firing patterns in the motor region move the paddle up or down. The sensory region is provided with sensory feedback about the position of the ball, but also with a predictable stimulus when the ball hits the paddle and a random stimulus when the paddle misses the ball. Over time, the neurons learn to avoid the random stimulation by hitting the ball more often.
The interesting aspect is that the network seems to learn based on an intrinsic preference for predictable as opposed to unpredictable stimuli. The authors interpret this result as supportive evidence for the free energy principle, because the systems seems to learn the game in order to escape punishment by the random and unpredictable stimulus.
I have however some doubts about the interpretation of the results and also about the conceptualization. First, it is strange that predictable and unpredictable stimuli are used to reward or punish the system. This is not how, according to my understanding, the free energy principle works. One would rather expect the the system (the ball/paddle interaction) to be modeled by the neuronal network and therefore become predictable. There would not be any use of additional reinforcement by predictable stimuli as reward. – Interestingly, in Bakkum et al. [4], in contrast, the negatively reinforcing stimulus was patterned while the stabilizing, positively reinforcing stimulus was random. This fact shows that different stimuli are used for different purposes, and interpretations of their effect on the network depends on the conceptual framework of the paper.
Second, it is strange that the predictable stimulus (75 mV at 100 Hz over 100 ms; unfortunately, the duty cycle is not stated) and the unpredictable stimuli (150 mV at 5 Hz over 4000 ms) differ quite a bit in terms of stimulation strength, duration and frequency of stimulation. One needs to make oneself aware of the fact that in reality the “predictive stimulus” is a high-frequency tetanus stimulation. Such tetanic stimuli are known to be able to drive long-term potentiation (LTP). It is not hard to imagine that the slower unpredictable stimulation results in long-term depression (LTD), not by means of being unpredictable but by means of its frequency and duration.
Therefore, an alternative and, in my opinion, much more parsimonious explanation of the results is that the system does not try to minimize surprising/unpredictable results, but that it potentiates neuronal patterns that precede successful performance by tetanic stimulation. I am therefore not convinced that Kagan et al. demonstrated a phenomenon that can be linked to predictive processing or the free energy principle in the way they describe it.
However, I would also like to highlight the positive sides of the paper: the figures are well-designed; a preprint is available; the experiments were done with several conditions which allow for comparisons across conditions (e.g., different cell lines); and the experimental system was characterized with several complementary methods (including IHC, EM, qPCR).
Conclusion
The fact that cultured neuronal networks can interact with a closed-loop and learn to optimize these interactions is quite fascinating. The interpretation of such behavior as “learned stimulation avoidance” [6], “autopoiesis” [8] or a reflection of the “free energy principle” [6,9] is certainly intriguing. However, it might rather serve as a metaphor or a high-level description and does not really provide a deeper analysis or understanding of the underlying mechanisms. One possible starting point to investigate the mechanisms of such learning could be the STDP rules that were found to be consistent with the learning behavior in simulation studies [5,6]. It would be possible to make predictions about how spike sequences evolve over learning in the dish, and to test those predictions in the experiment.
It is remarkable how limited the performance of the cultured in vitro systems is when they were trained to control a virtual agent or a game. The performances are, seemingly without exceptions, barely above chance level, and nowhere close to mastering the virtual world. Years ago, deep Q-learning has achieved performances that are close to perfection in video games way more complex than “pong”. I do not think that anybody should make a point of “intelligence in a dish” when the dish can barely process a binary input.
However, I am still somehow intrigued by the experimental findings, especially those made initially by Shahaf and Marom [1,2]. Would it be possible to observe the same behavior with a more naturalistic network, for example a cultured slice, or an ex vivo explant of a brain, or even a brain region in a living animal? For example, one could use optogenetics to stimulate a subset of cortical neurons in the mouse (“sensory” neurons), use calcium imaging or electrophysiology to record from another subset of neurons in the same brain area (“motor” neurons) and stop the stimulation once the “motor” neurons show a specific activity pattern. Using this experimental design, one could test for example whether the learning by stimulation avoidance can also be elicited in vivo.
Another aspect that might deserve attention is the apparent dependence of plasticity processes on a strong stimulus. In the experiments by Shahaf et al. [1], the stimulus co-occurs with the activity pattern that is then modified by plasticity. In Bakkum et al. [4], the plasticity-inducing stimulus is a tetanic stimulation following the activity pattern. Very similarly, in Kagan et al. [9], the tetanic stimulus is directly following the activity pattern that is strengthened afterwards. The observed effect could therefore be the reflection of a very coarse form of plasticity which occurs in a network that is strongly stimulated by an external stimulus that somehow reinforces previous activity patterns.
Overall, from all these studies it becomes clear that networks of cultured neurons do indeed seem to show some level of systems-level learning when integrated into a closed loop. I have the impression that the plasticity induced (e.g., by a strong tetanic stimulation) is not very naturalistic. Despite this limitation, it would be interesting to investigate experimentally what plasticity rules underlie such behavior. It is likely that the plasticity studied in slices since the ’90s is in some similar way artificial since it does not integrate neuromodulation or realistic levels of external calcium. And still these slice experiments brought forward useful concepts that can be tested in living organisms. Similarly, I think there might be interesting aspects of studying plasticity rules in cultered neurons in closed loops. But I do not think that it is of any use to frame such cultured networks as “synthetic biological intelligence” [9] or to overinterpret the results in a theoretical framework of choice – in particular if the performance of this “intelligence” remains so much lower than the lowest standards of both biological and artificial neural networks.
References
[1] Shahaf, Goded, and Shimon Marom. Learning in networks of cortical neurons. Journal of Neuroscience 21.22 (2001): 8782-8788.
[2] Marom, Shimon, and Goded Shahaf. Development, learning and memory in large random networks of cortical neurons: lessons beyond anatomy. Quarterly reviews of biophysics 35.1 (2002): 63-87.
[3] DeMarse, Thomas B., et al. The neurally controlled animat: biological brains acting with simulated bodies. Autonomous robots 11.3 (2001): 305-310.
[4] Bakkum, Douglas J., Zenas C. Chao, and Steve M. Potter. Spatio-temporal electrical stimuli shape behavior of an embodied cortical network in a goal-directed learning task. Journal of neural engineering 5.3 (2008): 310.
[5] Chao, Zenas C., Douglas J. Bakkum, and Steve M. Potter. Shaping embodied neural networks for adaptive goal-directed behavior. PLoS computational biology 4.3 (2008): e1000042.
[6] Sinapayen, Lana, Atsushi Masumori, and Takashi Ikegami. Learning by stimulation avoidance: A principle to control spiking neural networks dynamics. PloS one 12.2 (2017): e0170388.
[7] Keller, Georg B., and Thomas D. Mrsic-Flogel. Predictive processing: a canonical cortical computation. Neuron 100.2 (2018): 424-435.
[8] Masumori, Atsushi, et al. Neural autopoiesis: Organizing self-boundaries by stimulus avoidance in biological and artificial neural networks. Artificial Life 26.1 (2020): 130-151.
[9] Kagan, Brett J., et al. In vitro neurons learn and exhibit sentience when embodied in a simulated game-world. Neuron 110.23 (2022): 3952-3969.

Pingback: Annual report of my intuition about the brain (2021) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2020) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2019) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain | A blog about neurophysiology
Excellent, thoughtful analysis of this under-appreciated field I dedicated my career to. Thank you! If Kagan’s paper gets people talking about these useful in vitro models for brain-like computation, I am happy. I note that our work published in 2008 showing goal-directed learning of animats controlled by both simulated and living networks used fairly light stimulation, compared to our and others’ work using tetanus. I think SO much could be done (as you suggested) to explore the mechanisms of how to get spatially-controlled (meaning culture dish space) plasticity in vitro using a variety of burst controlling, attention-getting, probing, and random stimuli, as we used. You might also look at our more recent work using optogenetic stimuli to induce slow learning (called homeostatic plasticity) in cultured nets.
See:
Newman, J. P., Fong, M-f, Millard, D. C., Whitmire, C. J., Stanley, G. B., & Potter, S. M. (2015) Optogenetic feedback control of neural activity. eLife 2015;4:e07192 Online Open-Access Paper: https://elifesciences.org/content/4/e07192
Fong, M.-F., Newman, J. P., Potter, S. M., & Wenner, P. (2015). Upward synaptic scaling is dependent on neurotransmission rather than spiking. Nature Communications, 6, 6339. Online Open-Access Paper:
http://www.nature.com/ncomms/2015/150309/ncomms7339/full/ncomms7339.html
Hi Steve,
thank you very much for your feedback and comment, and in particular for pointing out the different stimulus setting in your 2008 paper!
I’ll check out the newer papers from your lab soon once I have some time for reading again!
Best wishes,
Peter
Pingback: Annual report of my intuition about the brain (2023) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2024) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2025, part I) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2025, part II) | A blog about neurophysiology
Pingback: Annual report of my intuition about the brain (2025, part III) | A blog about neurophysiology